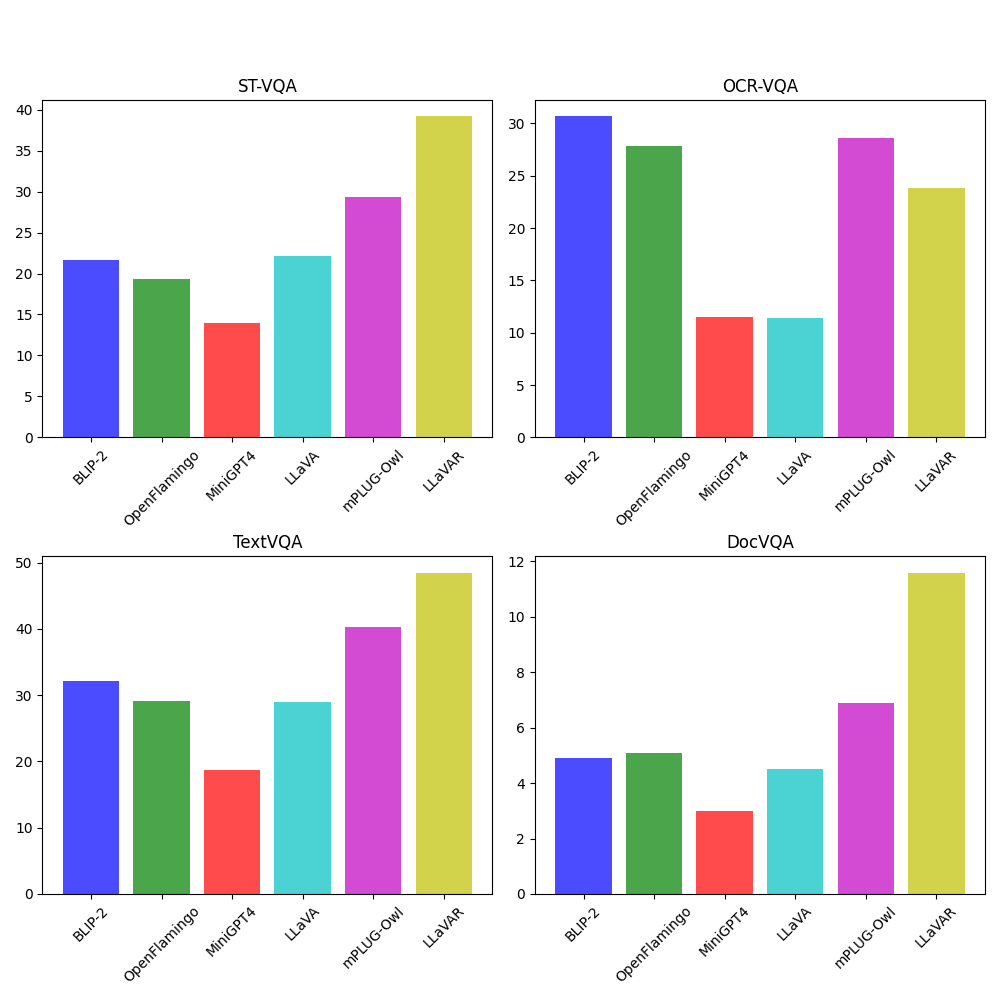LLaVAR: The LLaVA model that can Read texts within images.
Abstract
Instruction tuning unlocks the superior capability of Large Language Models (LLM) to interact with humans. Furthermore, recent instruction-following datasets include images as visual inputs, collecting responses for image-based instructions. However, visual instruction-tuned models cannot comprehend textual details within images well. This work enhances the current visual instruction tuning pipeline with text-rich images (e.g., movie posters, book covers, etc.). Specifically, we first use publicly available OCR tools to collect results on 422K text-rich images from the LAION dataset. Moreover, we prompt text-only GPT-4 with recognized texts and image captions to generate 16K conversations, each containing question-answer pairs for text-rich images. By combining our collected data with previous multi-modal instruction-following data, our model, LLaVAR, substantially improves the LLaVA model's capability on text-based VQA datasets (up to 20% accuracy improvement) while achieving an accuracy of 91.42% on ScienceQA. The GPT-4-based instruction-following evaluation also demonstrates the improvement of our model on both natural images and text-rich images. Through qualitative analysis, LLaVAR shows promising interaction (e.g., reasoning, writing, and elaboration) skills with humans based on the latest real-world online content that combines text and images.
[UPDATE 07/05] Model checkpoint (delta) available on Huggingface.
[UPDATE 06/29] Initial Release of Data/Code/Model. Huggingface is on the way!
Enhanced Visual Instruction Data with Text-Rich Images
Based on the LAION dataset, we collect 422K pretraining data based on OCR results. For finetuning data, we collect 16K high-quality instruction-following data by interacting with langauge-only GPT-4. Note that we also release a larger and more diverse finetuning dataset below (20K), which contains the 16K we used for the paper. The instruction files below contain the original LLaVA instructions. You can directly use them after merging the images into your LLaVA image folders. If you want to use them independently, you can remove the items contained in the original chat.json and llava_instruct_150k.json from LLaVA.
Images are all text-rich images from LAION, where we apply different filtering rules for pretraining and finetuning.
Pretraining Images
Finetuning Images
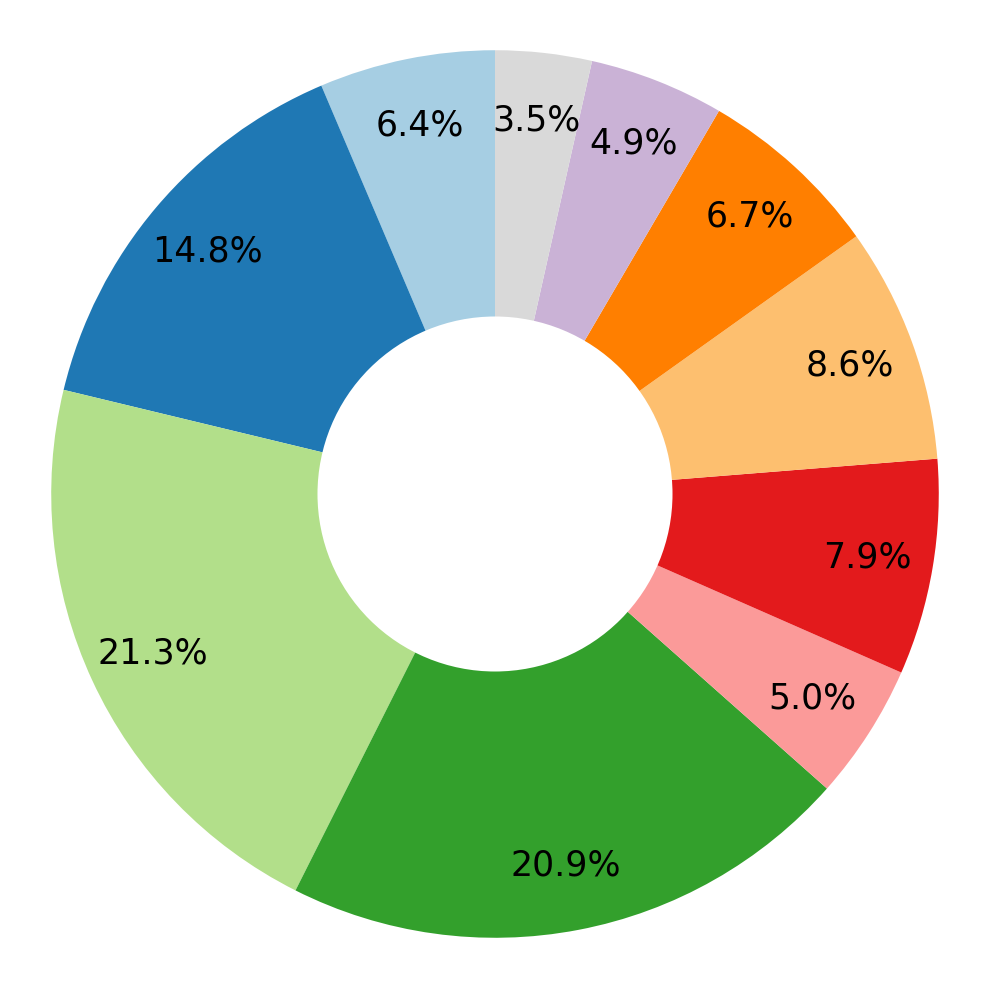
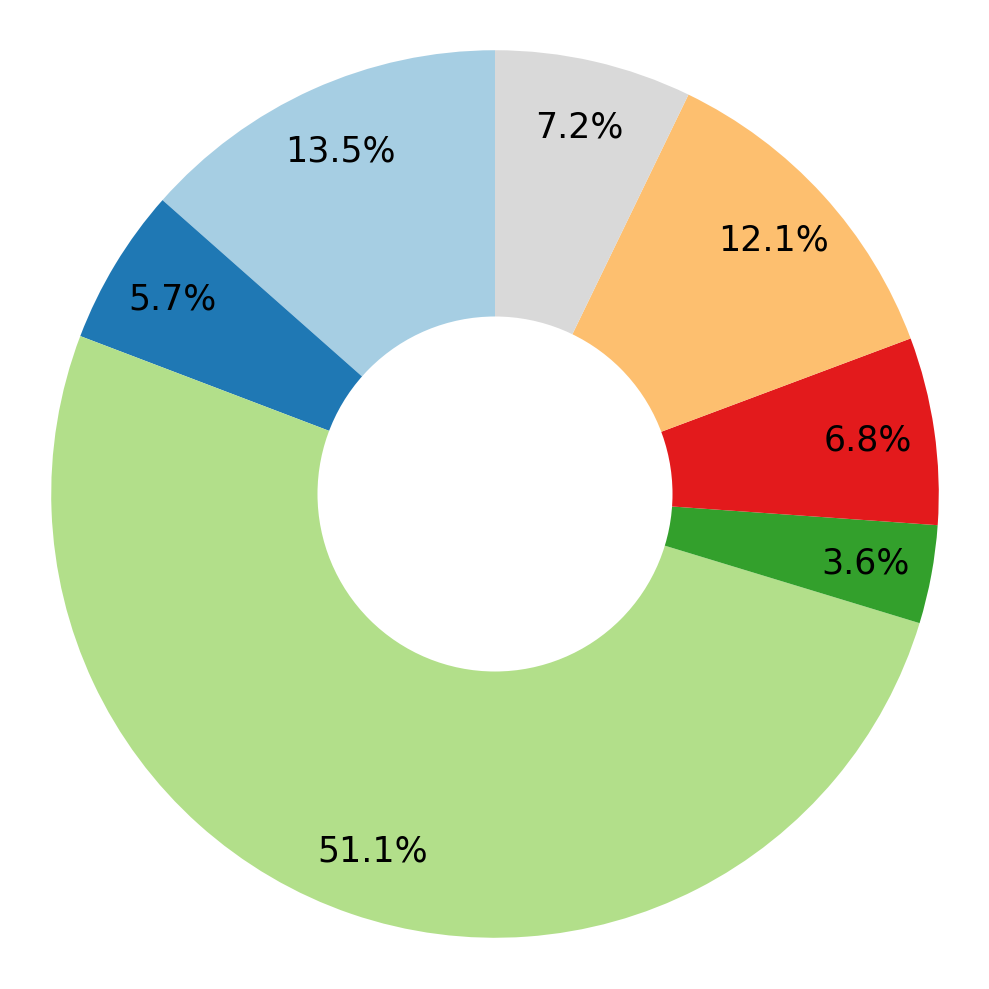
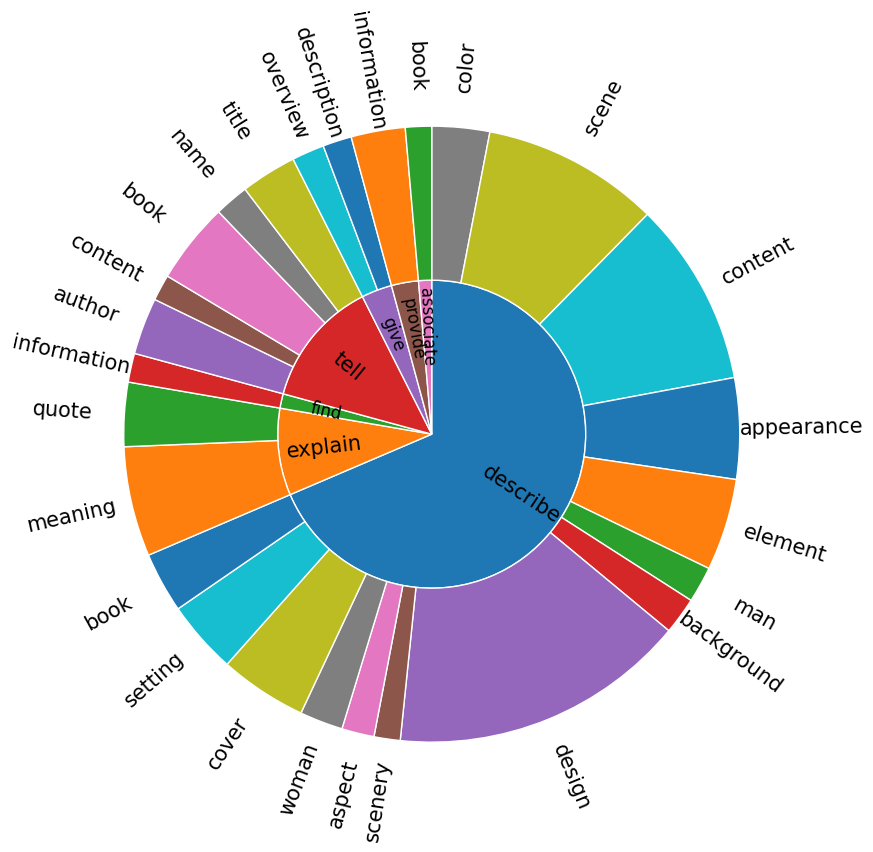
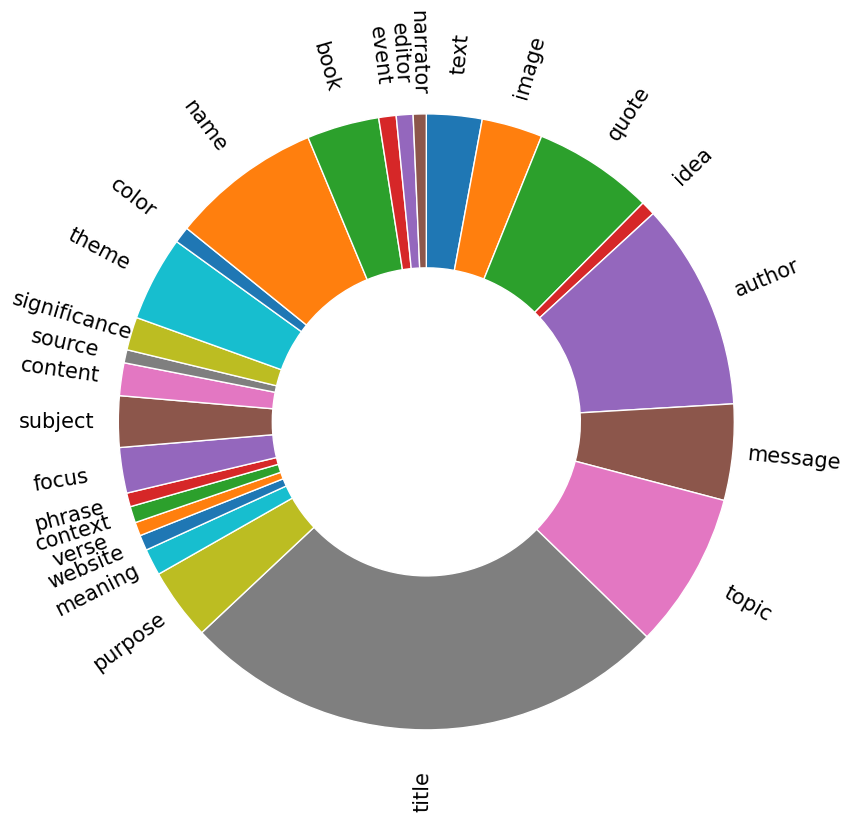
We visualize the root verb-noun pairs and objects that are being asked in instructions generated by GPT-4.
Verb-Noun Pairs
Objects
Performance
We evaluate the performance of LLaVAR on four text-based VQA datasets: ST-VQA, OCR-VQA, TextVQA, and DocVQA. LLaVAR also achieves an accuracy of 91.42% on ScienceQA.
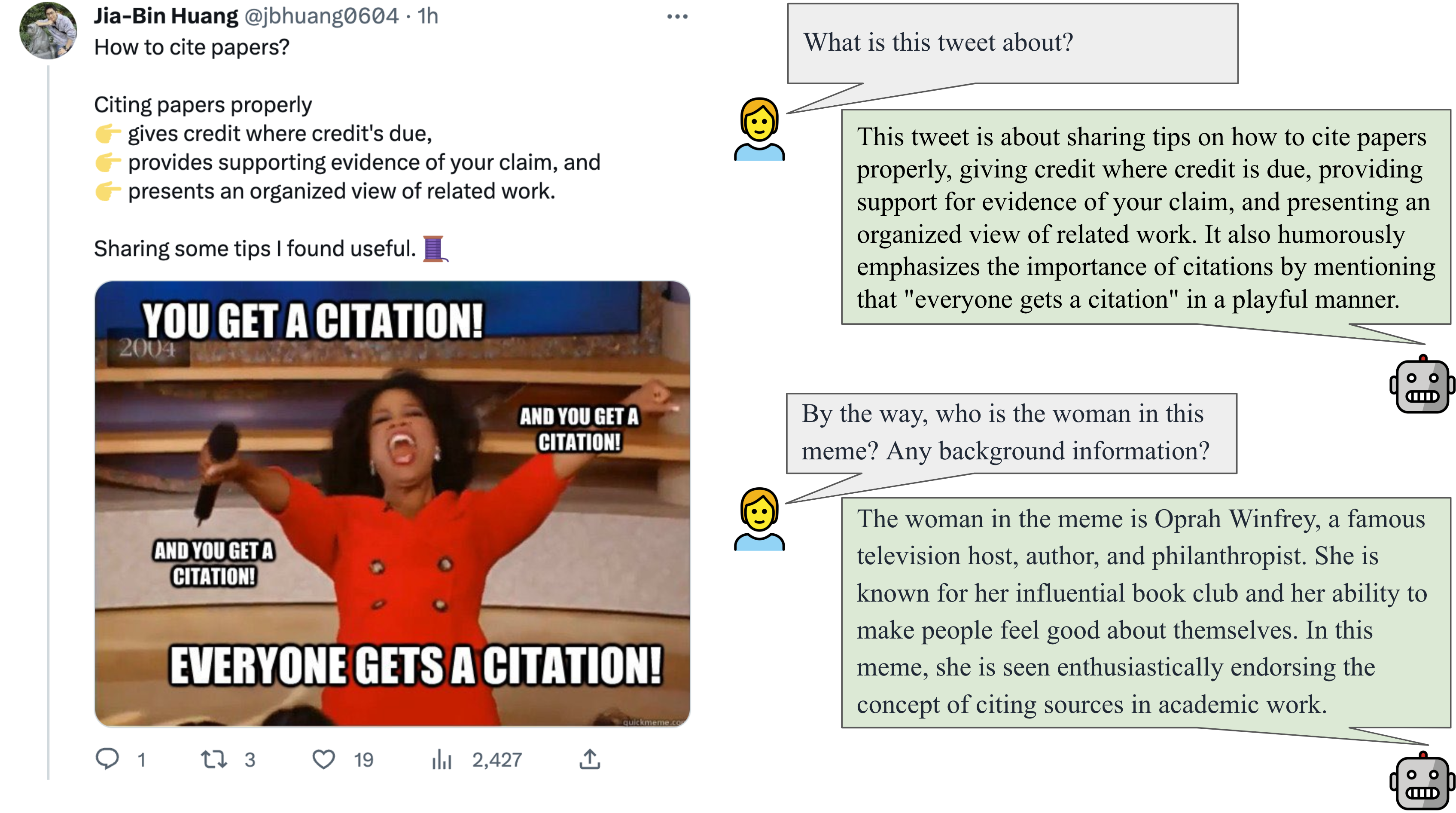
We show more instruction-following examples below:
BibTeX
@misc{zhang2023llavar,
title={LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding},
author={Yanzhe Zhang and Ruiyi Zhang and Jiuxiang Gu and Yufan Zhou and Nedim Lipka and Diyi Yang and Tong Sun},
year={2023},
eprint={2306.17107},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna, GPT-4 and LLaVA. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.